

A free, copy & paste Google Apps Script #
Redirect-chains are something you need to analyse a lot when dealing with migrations, redirects, or broken link building: it's a thing.
With this post I am following up on my earlier post about more advanced web scraping with Google Sheets. This time around I present to you: a dedicated bulk redirect-chain checker.
No need to install anything. Just copy & paste the code in the right place (follow the instructions below), call the custom function =scraper(url) and off you go.
You can easily use it for a lot of URLs: 1k - 5k maybe even (until Google Sheets starts complaining about Too Many Requests).
Step 1: Add the Cheerio library to your sheet #
Did you know you can load external libraries into Google Apps and so use their goodness? For this, I've used Cheerio, which basically mimics jQuery's element selection easyness.
-
1.
In the Google Sheet you want to use this script with, go to
Extensions>Apps Script -
2.
Now you’re in the In Apps Script interface. Go to
Librariesin the sidebar to the left, and click the+button -
3.
Copypaste the following library ID:
1ReeQ6WO8kKNxoaA_O0XEQ589cIrRvEBA9qcWpNqdOP17i47u6N9M5Xh0 -
4.
Click
Lookup, select the highest number from the list, and clickAdd
Congrats! Now you’ve added the scraping power of Cheerio to your Apps Script! This will enable you to use css selectors instead of xpath, which is way easier (thank me later).
Also, for those of you familiar with jQuery: it uses a familiar syntax for selecting stuff ;)
Step 2: copy paste this Apps Script #
-
-
Now you’re in the In Apps Script interface. Go to
Filesin the sidebar to the left, and click theCode.gsmenu item. -
-
Select all code in the field to the right, and delete the
function myFunction() {}example code -
-
Now replace it with the following code:
/**
* Processes a given URL to extract and return data in a format compatible with Google Sheets.
* It captures HTTP headers, HTML meta tags, and logs any remarks during processing.
*
* @param {string} url - The URL to process, or an empty string if no URL is provided.
* @return {Array} - Results formatted for Google Sheets.
*/
function scraper(url) {
let result = [];
// Initialize objects to store HTTP header, HTML meta tags, and log information
let http = initializeHttpObject(url);
let html = initializeHtmlObject();
let logs = { remarks: [] };
// If no URL is provided, only return column headers
if (!url) {
result.push(Object.keys(http).concat(Object.keys(html), Object.keys(logs)));
return result;
}
// Fetch the URL and reverse the order of results for processing
let output = fetchUrl(http.requestedUrl, http.chainLength);
output = output.reverse();
// Process each item in the fetch response
for (let i = 0; i < output.length; i++) {
let call = output[i].call;
// Process individual call if it exists
if (call) {
processCall(call, http, html, logs);
}
}
// Prepare the final result after processing all calls
finalizeHttpObject(http, logs);
result.push(Object.values(http).concat(Object.values(html), Object.values(logs)));
return result;
}
// Initialize HTTP object with default values for each property
function initializeHttpObject(url) {
return {
requestedUrl: url,
requestedUrlStatus: false,
loadedUrl: false,
loadedUrlStatus: false,
fullChain: [],
allLocations: [],
allStatusCodes: [],
chainLength: 0,
httpxrobots: []
};
}
// Initialize HTML object with default false or null values
function initializeHtmlObject() {
return {
title: false,
robots: false,
canonical: false,
canonicalSameAsLoadedUrl: null
};
}
// Processes each call (response) in the fetch output
function processCall(call, http, html, logs) {
// Process URL redirection and status
if (call.location) {
http.fullChain.push(`${call.url} => ${call.status}, note: to a relative location: ${call.location}`);
} else {
http.fullChain.push(`${call.url} => ${call.status}`);
}
// Accumulate all status codes and update chain length for redirects
http.allStatusCodes.push(call.status);
if (call.status > 300 && call.status < 399) {
http.chainLength += 1;
}
// Store each URL and HTTP x-robots tag
http.allLocations.push(call.url);
http.httpxrobots.push(call.httpxrobots);
// Process HTML tags if HTML content is available
if (call.html) {
processHtmlTags(call.html, html, call.url);
}
// Store any remarks from processing
if (call.remarks) {
logs.remarks.push(call.remarks);
}
}
// Extracts and sets HTML tag information from the HTML parser
function processHtmlTags(htmlParser, htmlObject, url) {
htmlObject.title = htmlParser('title').first().text() || false;
htmlObject.robots = htmlParser('meta[name=robots]').attr('content') || false;
htmlObject.canonical = htmlParser('link[rel=canonical]').attr('href') || false;
htmlObject.canonicalSameAsLoadedUrl = (htmlObject.canonical === url);
}
// Finalizes the HTTP object by compiling and formatting data
function finalizeHttpObject(http, logs) {
// Set the status of requested and final loaded URLs
http.requestedUrlStatus = http.allStatusCodes[0];
http.loadedUrl = http.allLocations[http.allLocations.length - 1];
http.loadedUrlStatus = http.allStatusCodes[http.allStatusCodes.length - 1];
// Log error if the final loaded URL results in an error
if (http.loadedUrlStatus > 399) {
logs.remarks.push(`URL error: final loaded URL results in an error, status code: ${http.loadedUrlStatus}`);
}
// Concatenate various arrays into newline-separated strings for output
http.httpxrobots = http.httpxrobots.join('\n');
http.allLocations = http.allLocations.join("\n");
http.allStatusCodes = http.allStatusCodes.join("\n > ");
http.fullChain = http.fullChain.join("\n");
logs.remarks = logs.remarks.join("\n").replace("\n\n","\n");
}
/**
* Fetches a given URL and returns the response.
* Handles HTTP requests, follows redirects up to a specified limit, and parses the response.
*
* @param {string} url - The URL to fetch.
* @param {number} chainLength - The current length of the redirect chain.
* @return {Object} - The response from the fetch operation.
*/
function fetchUrl(url, chainLength) {
let result = [];
const chainLimit = 10; // Maximum number of redirects to follow
const chainWarning = 3; // Number of redirects after which to issue a warning
try {
let options = configureRequestOptions();
// Fetch URL if provided
if (url) {
let response = UrlFetchApp.fetch(url, options);
let row = {
url: url,
status: response.getResponseCode(),
httpxrobots: response.getHeaders()['X-Robots-Tag'] || '',
location: response.getHeaders()['Location'] || '',
html: response.getContentText() ? Cheerio.load(response.getContentText()) : null,
remarks: ''
};
// Handle URL redirection
if (row.location && chainLength < chainLimit) {
let correctedLocation = parseUrlForRedirect(row.location, url);
row.location = correctedLocation.fullUrl;
result = result.concat(fetchUrl(correctedLocation.fullUrl, chainLength + 1));
}
// Add warning or limit remarks based on redirect chain length
if (chainLength === chainWarning) {
row.remarks += `Warning: Redirect chain length has reached ${chainWarning}.`;
}
if (chainLength >= chainLimit) {
row.remarks += `Limit reached: Stopped following redirects at chain length ${chainLimit}.`;
}
// Add the row to the result
result.push({ call: row });
}
} catch (error) {
// Push error information to the result
result.push({ error: error.toString() });
}
return result;
}
/**
* Configures and returns options for the HTTP request.
*
* @return {Object} - Object containing configured request options.
*/
function configureRequestOptions() {
let options = {
'muteHttpExceptions': true,
'followRedirects': false // Manually handle redirects
};
// Additional configuration can be added here (e.g., headers, authorization)
return options;
}
/**
* Parses a URL for redirection, handling relative URLs.
* Constructs a full URL if a relative path is provided.
*
* @param {string} location - The location header from the response.
* @param {string} currentUrl - The current URL being processed.
* @return {Object} - Object containing the full URL for redirection.
*/
function parseUrlForRedirect(location, currentUrl) {
// Handle relative URLs by constructing a full URL
if (location.startsWith('/')) {
let { protocol, host } = parseUrl(currentUrl);
return { fullUrl: `${protocol}://${host}${location}` };
}
return { fullUrl: location };
}
/**
* Parses a given URL and returns its components.
* Components include protocol, host, port, path, query, and fragment.
*
* @param {string} url - The URL to parse.
* @return {Object} - An object containing the components of the URL.
*/
function parseUrl(url) {
let match = url.match(/^(http|https|ftp)?(?:[:\/]*)([a-z0-9.-]*)(?::([0-9]+))?(\/[^?#]*)?(?:\?([^#]*))?(?:#(.*))?$/i);
let components = {
protocol: match[1] || '',
host: match[2] || '',
port: match[3] || '',
path: match[4] || '',
query: match[5] || '',
fragment: match[6] || ''
};
return components;
}
Some images to see it in action #
So just to be sure. The steps you take look like this:
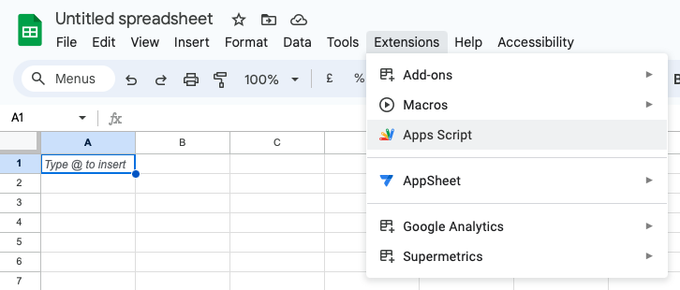
Go to Extensions > Apps Script
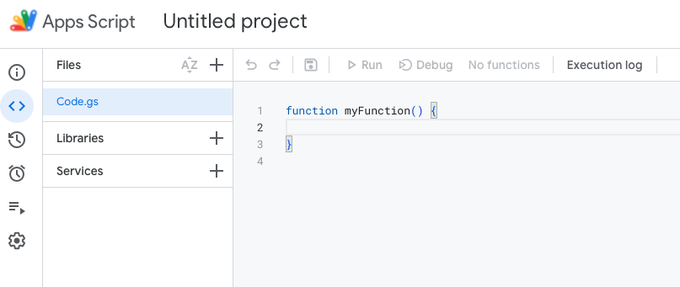
Delete the placeholder code, and optionally rename the script and the project (I renamed them to scraper.gs and 'Eikhart - Redirects', respectively.)
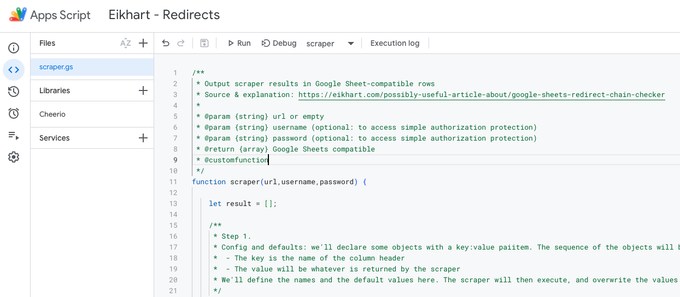
And this is what you should see after you've added Cheerio and copy pasted this script
That's it. Now you can give this function a URL, and it will return all kinds of stuff about redirects, redirect chains, locations, status codes, and even canonicals for you. I'll show you how.
Step 3: use it #
There are three ways to use it:
-
1.
Use
=scraper()to only output column headings -
2.
Use
=scraper(url)to output everything the tool finds for that given URL -
3.
Use
=scraper(url,username,password)to output everything the tool finds for that given URL, when that URL is hidden behind a simple authentication layer. Use this to debug redirects on an acceptation environment!
That's about it. Simply copy paste the code above to your Apps Script that is tied to the Google Sheet you're working in, and you're done.
All information below is additional: it shows you more about how it works, how to make the script auto-update at a certain refresh rate, and how to tweak the code a little bit to work with authorisation (e.g. for acceptation environments).
What kind of info is returned? #
This is a crawler that follows redirects and reports on them. It also checks some other URL-stuff, like canonical- and robot directives. It does a *lot* of things, but these are the highlights of what it returns:
-
-
The URL you requested (
requestedUrl) and itsstatuscodeof course, but also subsequent redirects, theirstatus codes, and theirlocations -
-
Several reports about the redirect chain: its
length, optionalwarningsor evenerrorsif the chain is too long, or if the chain is clean (no more than 1 different types of status codes), and if the final url (theloadedUrl) doesn't return an error -
-
The
canonicalandrobotstags (both in the HTMLheadandhttp headers). It also checks if the loadedUrl is thesameas the canonical (should be the same)
Some examples #
Adding a screenshot and all possible types of feedback would be too wide, so I'll just add some example highlights in a table:
| requestedUrl | requestedUrlStatus | loadedUrl | loadedUrlStatus | fullChain | canonical | canonicalSameAsLoadedUrl |
|---|---|---|---|---|---|---|
| http://nu.nl | 301 | https://www.nu.nl/ | 200 | http://nu.nl => 301 https://nu.nl/ => 301 https://www.nu.nl/ => 200 | https://www.nu.nl | FALSE |
| https://www.nu.nl | 200 | https://www.nu.nl | 200 | https://www.nu.nl => 200 | https://www.nu.nl | TRUE |
| http://centraalbeheer.nl/Autoverzekering | 301 | https://www.centraalbeheer.nl/verzekeringen/autoverzekering | 200 | http://centraalbeheer.nl/Autoverzekering => 301 https://centraalbeheer.nl/Autoverzekering => 301 https://www.centraalbeheer.nl/Autoverzekering => 301, note: to a relative location: /verzekeringen/autoverzekering https://www.centraalbeheer.nl/verzekeringen/autoverzekering => 200 | https://www.centraalbeheer.nl/verzekeringen/autoverzekering | TRUE |
| http://zilverenkruis.nl | 301 | https://www.zilverenkruis.nl/consumenten | 200 | http://zilverenkruis.nl => 301 https://zilverenkruis.nl/ => 301 https://www.zilverenkruis.nl/ => 301 https://www.zilverenkruis.nl/consumenten => 200 | https://www.zilverenkruis.nl/consumenten | TRUE |
| http://monchito.nl | 301 | https://eikhart.com/nl | 200 | http://monchito.nl => 301 https://eikhart.com/nl/ => 301 https://eikhart.com/nl => 200 | https://eikhart.com/nl | TRUE |
| https://eikhart.com/weird-redirect-loop/location1.php | 301 | https://eikhart.com/weird-redirect-loop/final.php | 404 | https://eikhart.com/weird-redirect-loop/location1.php => 301, note: to a relative location: /weird-redirect-loop/location2.php https://eikhart.com/weird-redirect-loop/location2.php => 303, note: to a relative location: /weird-redirect-loop/location3.php https://eikhart.com/weird-redirect-loop/location3.php => 302, note: to a relative location: /weird-redirect-loop/location4.php https://eikhart.com/weird-redirect-loop/location4.php => 307 https://eikhart.com/weird-redirect-loop/final.php => 404 | FALSE | FALSE |
| Pay special attention to the last URL ;) |
||||||
How to make this script even more dynamic #
By default, Google Sheets refreshes its data when the content of a cell (either a hardcoded text or the result of a formula) changes. You can however set a custom refresh interval when everything should change. For this, go to File > Settingsand choose between these options:
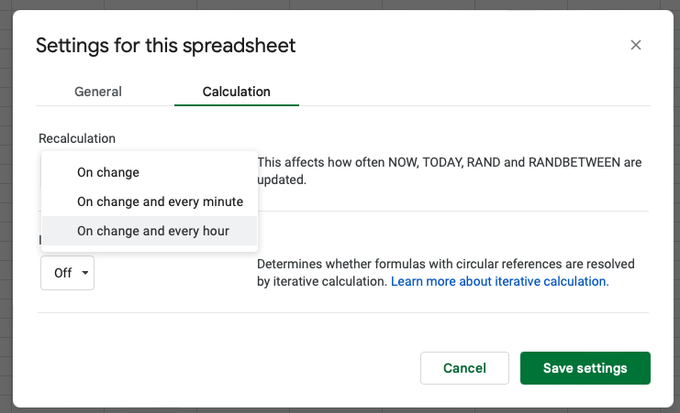
Default is onchange, but you can add an interval
Still not specific enough? What if you're changing redirects one by one, and you also want to check the redirected URLs one by one?
Easy!
Select the cell with the url in it and delete the contents. After that, undo (Ctrl-z(Windows) or cmd-z (macOS). Et voila: the scraper wil rerun immediately, but for only this cell.
What about authorization? #
When done right, the website should have an acceptation environment, and you as an SEO should have access to it. This is perfect to test redirects before they go live!
Or: the website is protected with something like Cloudflare and it's blocking you unless you send a specific header with each request. I got you covered!
The script contains a few common ways to deal with authorization. I have however, commented them out, so you need to uncomment and modify it with your specific credentials to make it work.
Look for this part in the code, and adjust accordingly:
// uncomment if you want to enter an area that is protected with basic auth
/**
* const basicAuthUser = "user";
* const basicAuthPass = "pass";
* options.headers = {
* "Authorization": "Basic " + Utilities.base64Encode(basicAuthUser + ":" + basicAuthPass, Utilities.Charset.UTF_8),
* }
*/
// uncomment if you want to enter an area that is protected with an authorization token
/**
* const token = "XXXXXXXXXXXXXXXXXXXXX";
* options.contentType: 'application/json',
* options.headers = {
* "Authorization" : token
* }
*/
// uncomment if you just need to send custom headers. I'll give you an example
/**
* options.headers = {
* "custom_header_key": "a-key",
* "custom_header_secret": "a-secret"
* }
*/That's it #
I hope you'll find it useful. I've been using this script for quite some years now for my own projects but never really shared it with the community. Long overdue!